Unicorn
Unicorn&&Unidbg
¶Unicorn简介
Unicorn是一个轻量级、多平台、多架构的CPU模拟器框架,使用Unicorn的API可以轻松控制CPU寄存器、内存等资源,调试或调用目标二进制代码
¶Unicorn安装
pip install unicorn即可
¶Unicorn使用
首先导入我们想要模拟执行代码需要的库模块,这里是x86
1 | from unicorn import * |
接着指定我们想要执行的数据必须是bytes型的数据
1 | code=bytes([0x55, 0x8B, 0xEC, 0x51, 0x8B, 0x55, 0x0C, 0xB9, 0xFF, 0x00, 0x00, 0x00, 0x89, 0x4D, 0xFC, 0x85, 0xD2, 0x74, 0x51, 0x53, 0x8B, 0x5D, 0x08, 0x56, 0x57, 0x6A, 0x14, 0x58, 0x66, 0x8B, 0x7D, 0xFC, 0x3B, 0xD0, 0x8B, 0xF2, 0x0F, 0x47, 0xF0, 0x2B, 0xD6, 0x0F, 0xB6, 0x03, 0x66, 0x03, 0xF8, 0x66, 0x89, 0x7D, 0xFC, 0x03, 0x4D, 0xFC, 0x43, 0x83, 0xEE, 0x01, 0x75, 0xED, 0x0F, 0xB6, 0x45, 0xFC, 0x66, 0xC1,0xEF, 0x08, 0x66, 0x03, 0xC7, 0x0F, 0xB7, 0xC0, 0x89, 0x45, 0xFC, 0x0F, 0xB6, 0xC1, 0x66, 0xC1, 0xE9, 0x08, 0x66, 0x03, 0xC1, 0x0F, 0xB7, 0xC8, 0x6A, 0x14, 0x58, 0x85, 0xD2, 0x75, 0xBB, 0x5F, 0x5E, 0x5B, 0x0F, 0xB6, 0x55, 0xFC, 0x8B, 0xC1, 0xC1, 0xE1, 0x08, 0x25, 0x00, 0xFF, 0x00, 0x00, 0x03, 0xC1, 0x66, 0x8B, 0x4D, 0xFC, 0x66, 0xC1, 0xE9, 0x08, 0x66, 0x03, 0xD1, 0x66, 0x0B, 0xC2]) |
指定我们想要代码模拟运行时的地址
1 | ADDRESS=0x400000 |
使用Uc类来初始化Unicorn实例,参数一是硬件架构、参数二是硬件模式,这里创建的环境是32位X86架构
1 | mu=Uc(UC_ARCH_X86,UC_MODE_32) |
使用mem_map()分配内存
1 | mu.mem_map(ADDRESS,2*1024*1024) |
将要模拟运行的代码写入内存中,使用mem_write(ADDRESS,code)
1 | mu.mem_write(ADDRESS,code) |
通过reg.write()可以设置寄存器的值
1 | mu.reg_write(UC_X86_REG_EDX,0x1234) |
使用emu_start()方法模拟运行
1 | mu.emu_start(ADDRESS, ADDRESS+len(code)) |
运行完毕后使用reg_read()方法读取寄存器的值即可
1 | data=mu.reg_read(UC_X86_REG_EDX) |
¶Unicorn使用案例
Flare-on4 3
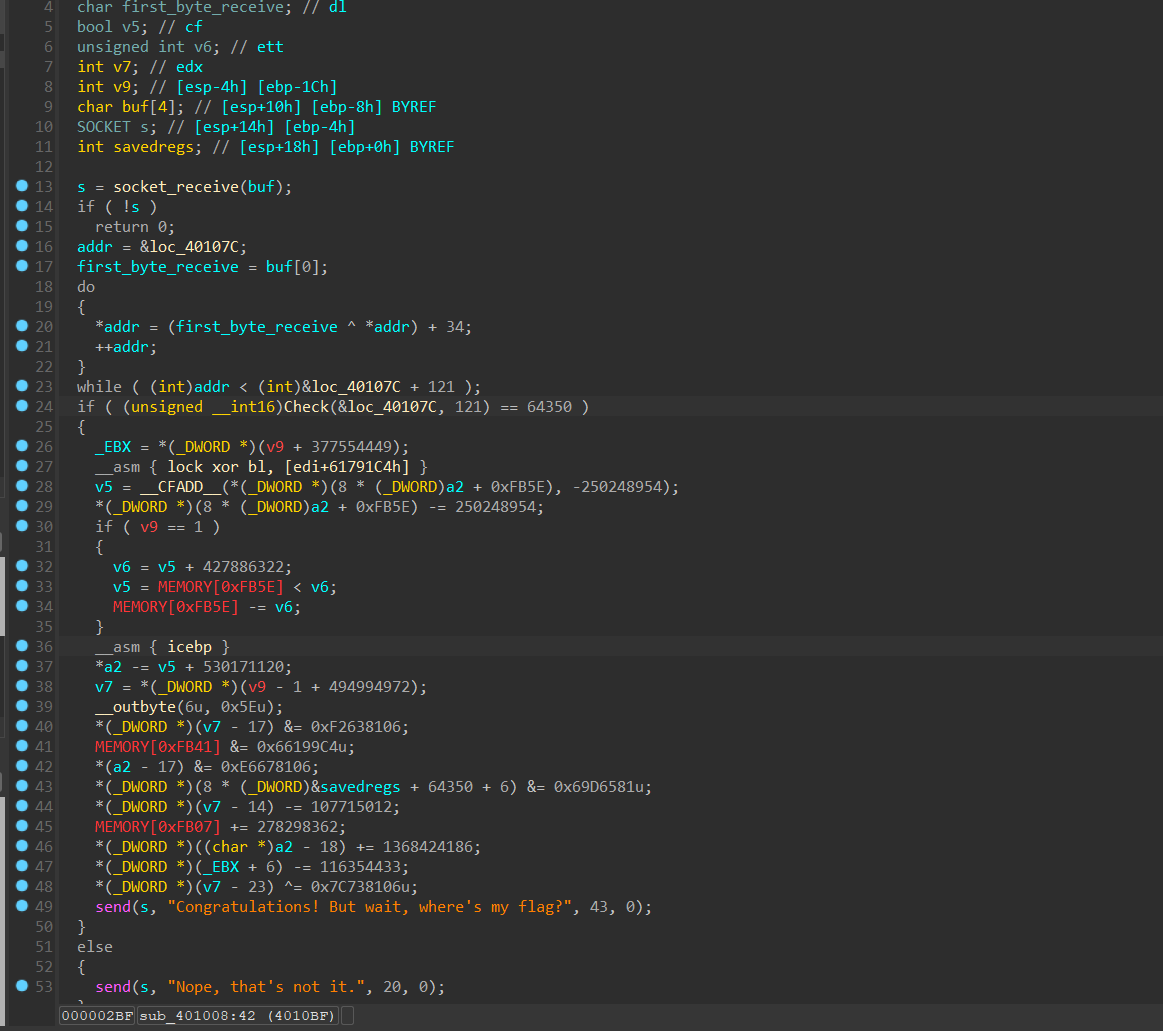
中间一大段无法被正确反编译的明显是被加密过的,而前面do……while进行的正是解密操作,经过socket_receive函数处理后的buf的第一个字节用于解密操作
进入socket_receive函数
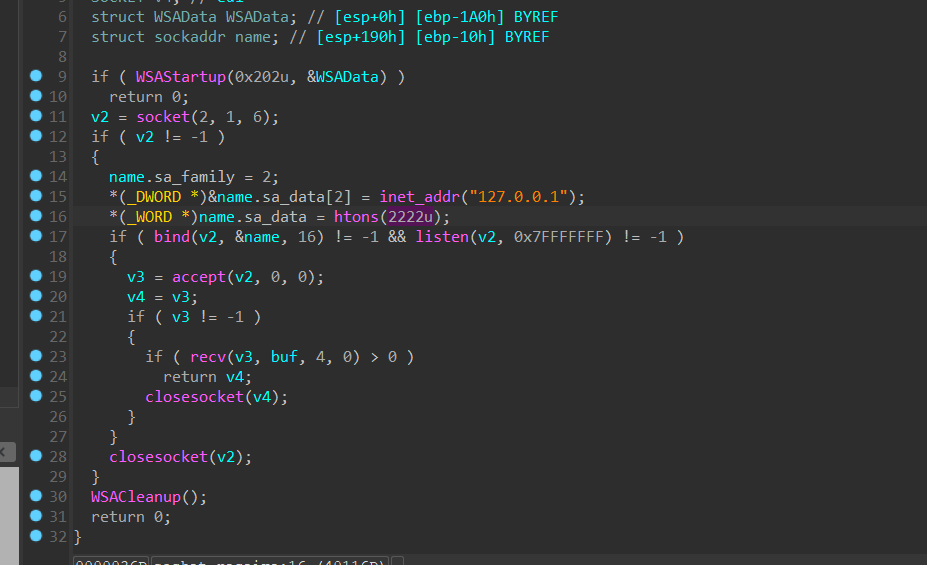
使用socket对本地的2222端口设置监听,accept函数如果没有接受到连接会一直处于阻塞状态,所以在这里会卡住

可以看到2222端口正在被监听
我们可以编写python脚本来发送数据
1 | from socket import * |
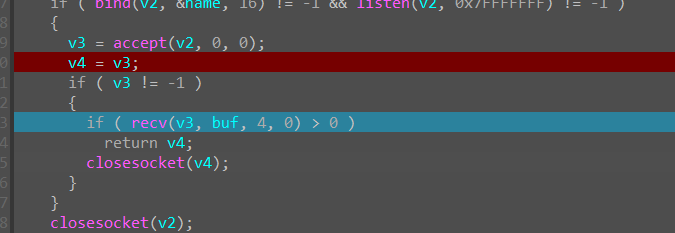
accept之后创建一个socket对象,然后将使用recv函数接收并存入buf中
然后就将我们发送数据的第一个字节作为key进行SMC自解密
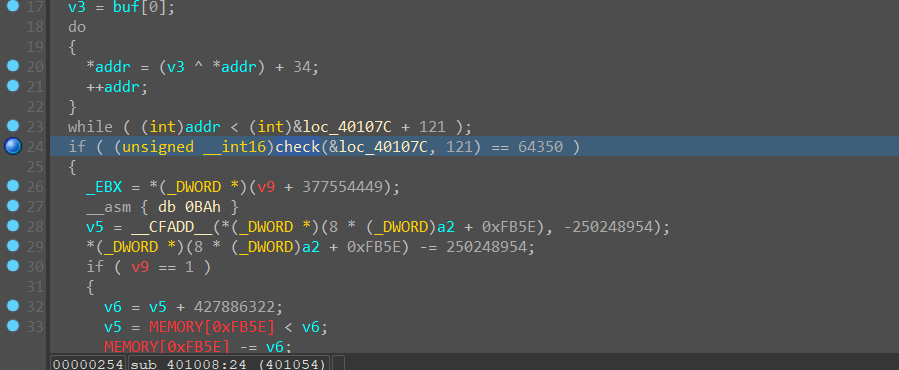
接着将SMC后数据的起始地址和长度121传入check进行校验
然后根据校验的情况send不同的数据到客户端
¶socket爆破
由于SMC解密用到的只有一个字节,所以我们可以爆破,不断传入数据直到接收到Congratulations! But wait, where’s my flag?
由于接收消息之后程序就直接关闭了,所以我们需要使用到os.startfile(exe)来运行程序,我们还需要将整数转为bytes型数据后发送,要用到struct.pack(“I”,data),其作用如下
- 按照指定格式将Python数据转换为字符串,该字符串为字节流,如网络传输时,不能传输int,此时先将int转化为字节流,然后再发送;
- 按照指定格式将字节流转换为Python指定的数据类型;
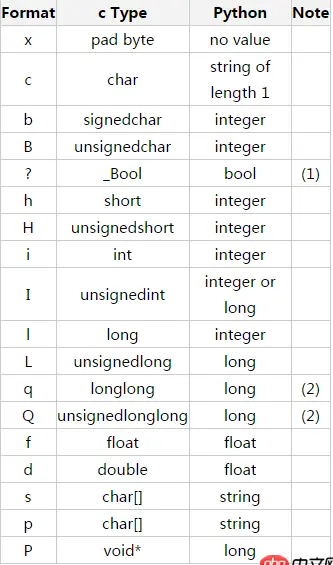
同时struct也可以指定大小端序

爆破脚本如下
1 | from socket import * |
¶Unicorn
也是采用爆破的方式,这里模拟运行的是check函数,不断将SMC解密后的数据和数据的长度写入Unicorn的内存中并执行check函数,直到其返回值为0xFB5E为止
首先我们需要提取出被加密的数据和要执行的代码的机器码并转为字节流
1 | enc_data = [0x33, 0xe1, 0xc4, 0x99, 0x11, 0x6, 0x81, 0x16, 0xf0, 0x32, 0x9f, 0xc4, 0x91, 0x17, 0x6, 0x81, 0x14, 0xf0, 0x6, 0x81, 0x15, 0xf1, 0xc4, 0x91, 0x1a, 0x6, 0x81, 0x1b, 0xe2, 0x6, 0x81, 0x18, 0xf2, 0x6, 0x81, 0x19, 0xf1, 0x6, 0x81, 0x1e, 0xf0, 0xc4, 0x99, 0x1f, 0xc4, 0x91, 0x1c, 0x6, 0x81, 0x1d, 0xe6, 0x6, 0x81, 0x62, 0xef, 0x6, 0x81, 0x63, 0xf2, 0x6, 0x81, 0x60, 0xe3, 0xc4, 0x99, 0x61, 0x6, 0x81, 0x66, 0xbc, 0x6, 0x81, 0x67, 0xe6, 0x6, 0x81, 0x64, 0xe8, 0x6, 0x81, 0x65, 0x9d, 0x6, 0x81, 0x6a, 0xf2, 0xc4, 0x99, 0x6b, 0x6, 0x81, 0x68, 0xa9, 0x6, 0x81, 0x69, 0xef, 0x6, 0x81, 0x6e, 0xee, 0x6, 0x81, 0x6f, 0xae, 0x6, 0x81, 0x6c, 0xe3, 0x6, 0x81, 0x6d, 0xef, 0x6, 0x81, 0x72, 0xe9, 0x6, 0x81, 0x73, 0x7c, 0x6a] |
接着将加密后的数据进行解密后写入Unicorn中
1 | def decode_bytes(key): |
Unicorn模拟执行部分
1 | def run_code(bytes): |
需要注意的是check函数是有参数的,所以我们需要先设置栈和ESP,并且将解密数据的地址和解密数据的长度按照顺序存入栈中,根据IDA的栈视图可以更快地确定函数参数在栈中地关系
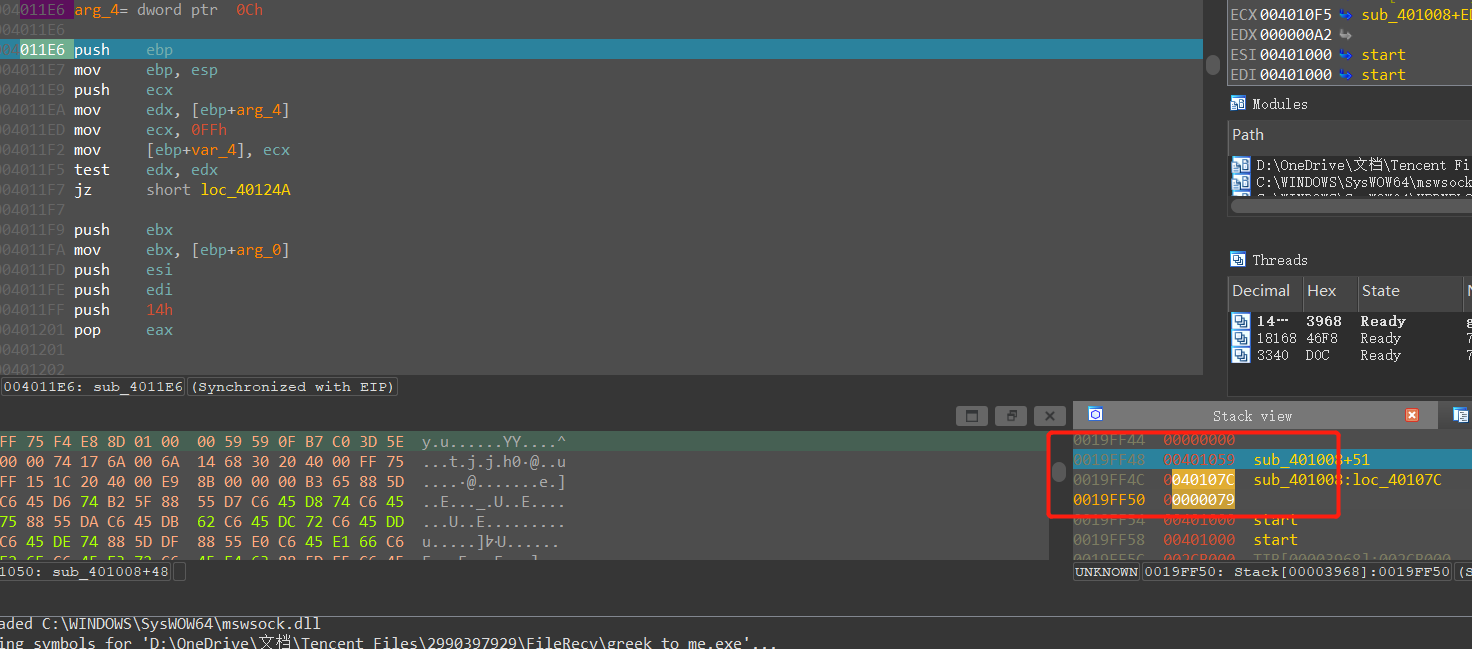
爆破主体部分
1 | for i in range(0, 256): |
当check的函数的返回值等于0xFB5E之后
使用capstone中的Cs指定代码的架构和模式,disasm(bytes_code,offset)将bytes字节流转为汇编代码,disasm的参数分别是机器码的字节流和偏移(我们指定)
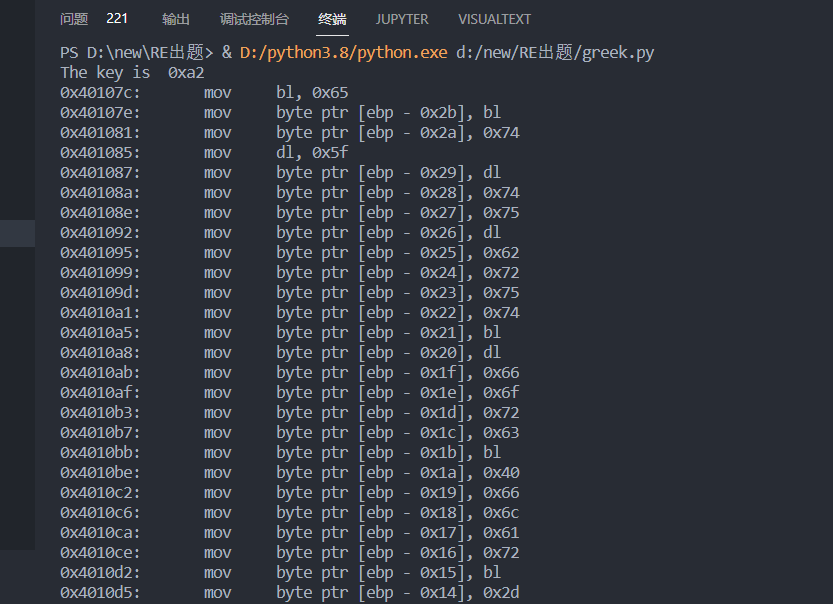
完整代码
1 | from pickletools import bytes1 |
¶Unicorn-Hook
Unicorn还提供了hook_add()方法来Hook
这种类型的hook在执行每条指令前都会先执行hook_code
hook_code函数 该函数需要以下参数:
- Uc实例
- 指令的地址
- 指令的大小
- 用户数据(我们可以在hook_add()的可选参数中传递这个值)
1 | mu.hook_add(UC_HOOK_CODE,hook_code,start,end) |
¶Unicorn执行程序
Unicorn执行程序其实和前面的执行一段执行是类似的,唯一不同的就是需要read文件。最后按照IDA中的偏移来设置开始执行的地址,这样方便我们对照和写入数据。
但是要注意有些外部函数比如printf之类的,由于加载进虚拟内存中所以无法使用
通过Hook来修改修改EIP/RIP跳过执行即可
对于写入内存中的int型数据首先使用struct.pack()转为bytes,然后再写入,也可以通过pwntools直接转换

1 | from unicorn import * |
¶keystone和capstone
keystone将汇编代码转为机器码,而capstone将机器码转为汇编代码
¶Unidbg
Unibdg是基于unicorn的,项目地址
git clone下来后导入IDEA
打开在TTEncrypt运行,导入成功会得到如下输出