PE文件结构
¶PE文件
主要有exe、dll、sys文件,这些都是可执行文件
exe由多个exe文件组成,dll之类的
¶PE文件头解析
在内存中和硬盘中数据几乎是一样的,但是存在差异,且程序开始的位置不同,所以可以知道存储信息的位置是可以改变的
根据不同的功能分了不同的节,也就是程序不同的块,这样做1、可以节省硬盘空间,在内存中占用空间大于硬盘占用空间(节之间的间隔较小)
2、节省内存,当程序需要多开的时候,只需要将可读可写的数据段重新复制一份即可,不需要对只读的数据进行复制
¶硬盘(文件)对齐和内存对齐
目的都是为了提升读写的速度
老的编译器,硬盘对齐是200h个字节**(当不够200h字节,会自动填充)**,内存对齐是1000h个字节,所以PE结构执行(操作系统运行exe文件)时会发生拉伸的过程,即在内存中占用空间大于硬盘占用空间
新的编译器在硬盘和内存都采用1000h,这是因为编译器发展,这样内存和硬盘对齐一样,运行时可以减少运算,这样虽然牺牲了空间,但是缩短了时间
¶PE磁盘文件与内存映像结构图
块表(节表)概括节的基本信息(起始和终止位置,节的大小),DOS头和PE头对当前exe文件做的概要性描述(拉伸完后的大小,堆栈大小),节表存储信息

¶DOS头
DOS长度确定
解析exe文件时,先解析前两个字节,并通过DOS头找到exe文件真正开始的地方
第一个WORD MZSignature(e_magic)-MZ标记
最后一个LONG AddressOfNewExeHeader(e_lfanew)-指向了PE文件的真正开始地址

这里的0108表示从文件开始的地方计算0108个字节就是PE结构开始的地方
¶NT头
DOS头和NT头中间是一段空间,可以自由发挥,多与少不确定,我们可以在这一段写入shellcode( 利用软件漏洞而执行的代码 ),在程序中调用。有地址我们就可以访问和执行
PE的标记-DWORD Signature-四个字节
¶标准PE头-20字节

关键信息
enum IMAGE_MACHINE Machine-程序运行的CPU型号:0x0 任何处理器 /0x14C 386及后续处理器
WORD NumberOfSections-文件中存在的节的数量,如果需要新增或者合并节,就要修改这个值
time_t TimeDateStamp-文件创建时间,编译器填写
WORD SizeOfOptionalHeader-可选PE头的大小,32位PE文件默认E0h、64位PE文件默认为F0h 大小可以自定义.
struct FILE_CHARACTERISTICS Characteristics-每个位有不同的含义,可执行文件值为10F 即0 1 2 3 8位置1
这里的102拆成二进制

勾中即为1
¶可选PE头
结构


关键信息
enum OPTIONAL_MAGIC Magic-说明文件类型:10B 32位下的PE文件、20B 64位下的PE文件
DWORD SectionAlignment-内存对齐
DWORD FileAlignment-文件对齐
DWORD SizeOfCode-所有代码节的和,必须是FileAlignment的整数倍,编译器填的,不会被使用
DWORD SizeOfInitializedData-已初始化数据大小的和,必须是FileAlignment的整数倍,编译器填的,不会被使用
DWORD SizeOfUninitializedData-未初始化数据大小的和,必须是FileAlignment的整数倍,编译器填的,不会被使用
DWORD AddressOfEntryPoint-程序入口
DWORD BaseOfCode-代码开始的基址,编译器填的,不会被使用
DWORD BaseOfData-数据开始的基址,编译器填的,不会被使用
!!DWORD ImageBase-内存镜像基址(不从0开始是因为需要内存保护)
把文件拖入OD时会断在ImageBase+AddressOfEntryPoint这个地址,也就是OEP
程序入口可以修改-加壳
加壳之后入口点EP(RVA)和OEP(RAW)都会改变,但是内存镜像基址不变
内核重载:(有一些软件会通过hook技术,检测是否调用函数)相当于PEloader(加载)-把硬盘文件拷贝到内存中进而执行exe文件,但是在拷贝过程中还会有一个文件的缓冲区,这个缓冲区也是在内存中的。装载到内存时是以ImageBase为起点的
DWORD SizeOfImage-内存中整个PE文件的映射的尺寸,可以比实际的值大,但必须是SectionAlignment的整数倍,也就是PE文件在内存中被拉伸后的大小
DWORD SizeOfHeaders-所有头+节表按照文件对齐后的大小,否则加载会出错
DWORD CheckSum-校验和,一些系统文件有要求,用来判断文件是否被修改
DWORD SizeOfStackReserve-初始化时保留的堆栈大小
DWORD SizeOfStackCommit-初始化时实际提交的大小
DWORD SizeOfHeapReserve-初始化时保留的堆的大小
DWORD SizeOfHeapCommit-初始化时实际提交的大小
DWORD NumberOfRvaAndSizes-目录项数目
¶节表-每个节有28字节的信息
节表定位-DOS+PE+OPTIONPE
描述每个节的信息

节的结构

BYTE Name[8]是八个字节,不够补’\0’,在内存是0,所以不能使用char*,而要用char [9],且可以随便改

第二个成员是union Misc,双字,是该节在没有对齐前的真实尺寸,该值可以不准确(可能被别的软件加工过),但是不会妨碍运行,里面的成员DWORD VirtualSize-存放PE文件放入内存时的数据宽度,他的值可能大于文件对齐后的数据宽度(SizeofRawData),这是因为未初始化的变量不会被存入文件中
第三个成员-DWORD VirtualAddress-节区在内存中的相对偏移(拉伸-内存对齐后的),加上ImageBase才是在内存中的真正地址(跟文件中无关)
第四个成员-DWORD SizeOfRawData-节在文件中对齐后的尺寸
第五个成员-DWORD PointerToRawData-节区在文件中的偏移,所以.text是从400h开始的(跟内存中无关)


第二个和第四个是在调试时使用的,编译完这四个默认为0
struct SECTION_CHARACTERISTICS Characteristics-节的属性
最后一个成员struct SECTION_CHARACTERISTICS Characteristics-里面有32位,但不是每一位都用
1 | --> 标志(属性块) 常用特征值对照表:<-- |
¶运行状态
拉伸完之后还需要进行一些准备步骤
先把文件对齐后的数据拷贝到内存中,根据SizeofHeades,直接copy,因为头和节表是不会变化的,但是节表后面不一定是节区,这是因为文件对齐和内存对齐不同
循环赋值节的内容,复制到内存的地方由节表信息里面的VirtualAddress决定,PointerToRawData决定了文件复制到内存的起始位置
复制数据的大小根据SizeofRawData(Misc也可以,但是如果MIsc存在大量未初始化数据,会变得很大,可能将下一节的信息也copy到内存中)

¶根据内存数据存储的位置查找在文件中的位置
假设内存开始位置是500000,数据在内存存储位置是501234
1、确定节
先确定偏移501234-500000
根据节的不同偏移(VirtualAddress)
1234>VirtualAddress
1234<VirtualAddress+Misc.VirtualSize
2、计算距离节初始位置的长度
1234-1000=234h
3、在文件中寻找
因为在文件中和在内存中距离节初始位置的长度相同,所以地址为400+234h
¶代码节空白区添加代码
MessageBoxA-四个参数,执行后会出现弹窗-一般exe都有这个函数-user32.dll里面
让程序执行我们的代码,需要先找到OEP,修改为call我们函数的地址,然后再jmp回到原程序的OEP
call=E8+四个字节,jmp=E9+四个字节
但是这四个字节不是直接的地址,需要进行计算
真正要跳转的地址=E8这条指令的下一行地址(当前指令地址+5,因为call长度是5)+X(X就是E8后边跟着的四个字节)
push=0x6A
所以我们要加的程序硬编码 = 6A 00 6A 00 6A 00 6A 00 E8 00 00 00 00 E9 00 00 00 00
我们加入的代码必须加在拉伸后的文件中,也就是内存中的,因为我们计算的地址是拉伸后的地址
¶添加代码过程-文件注入
1、先看代码空白区能不能填充那十八个字节——(SizeofRawData-VirtualSize)
2、找到添加的地方,假设我们开始是从1000h开始的,而SizeofRawData是1a0000,所以两者相加就是当前节结束的地址,而在1b0000之前为0的部分是代码块的空白部分
3、开始填充我们的那十八个字节
4、算地址,要计算内存对齐的地址,而不是文件对齐的,因为我们需要的是运行时的地址(内存对齐和文件对齐不同)
先找到MessageBoxA在内存中的地址,在OD里面使用命令bp MessageBoxA,按状态栏的B可以找到内存的地址
5、填充,注意小端序,E8跟着计算后的地址,E9跟着计算后的OEP(ImageBase+EntryPoint)
6、将原本的EntryOfPoint改为我们填充数据在内存中的地址
¶任意代码节空白区添加代码
从内存转为硬盘文件计算大小-最后一个节的初始位置+最后一个节的大小
¶新增节-添加代码
新增之后,修改NumberOfSections,节表信息,节表后面必须跟着一定长度的00数据(空白区),所以要计算增加之后SizeofHeaders会不会大于PointerOfRawData,并且在新增节最后加上一个节表信息长度的00
计算内存偏移VirtualAddress(RVA)时,根据上一个节区的VirtualAddress+(SizofRawData/VirtualSize[谁大加谁])按照内存对齐后的数
如果编译器在节表中加入一些数据,而我们不能修改,节表又不能断,只能将NT头前移(加入数据之前的),这样再去添加新的节表信息,就不会占用编译器加入的数据
当DOS到NT头大小不够开辟一个节表的信息,只能扩充最后一个节
¶扩大节-合并节-数据目录
扩大节:在内存中进行扩大,然后再还原回文件中,还原的时候要修改参数
1、拉伸到内存
2、分配新空间N=SizeofImage+Ex
3、将最后一个节的SizeOfRawdata和VirtualSize改为N
4、修改SizeofImage
合并节:合并之后节表有空间进行添加节区
VirtualSize=SizeofImage-VIrtualAddress
数据目录-里面存储各种表的信息

下面介绍几种比较重要的
¶DLL-动态链接库和静态链接库
使用的时候都需要include
程序编译的过程为将.h和.cpp等文件进行预编译,然后进行编译,再进行汇编,最后链接上(.a/.lib/.so/.dll)成为可执行文件
静态库、动态库区别来自【链接阶段】如何处理库(处理方式不同来区分),链接成可执行程序。分别称为静态链接方式、动态链接方式
¶静态链接
使用的时候需要include和#pragma comment(lib,“xxx.lib”)
因为头文件只包含函数声明,函数实现在lib文件中
即在链接阶段,将源文件用到的库函数与汇编生成的文件.o等合并(即函数被包含在exe文件中)生成可执行文件
好处:方便程序移植,因为可执行程序与库函数再无关系,放入任何环境当中都可以执行
缺点:可执行文件太大(因为包含了库函数),每次库文件升级都需要重新编译源文件,每个可执行程序都会合并库函数,存在很大的重复性,占用空间大
¶动态链接
两个程序应用一个库,目标文件在内存中只有一份,供所有程序使用,但是可移植性太差,如果两台电脑运行环境不同,动态库存放位置不同,可能会导致程序运行失败
¶隐式链接
1、将dll,lib文件添加到调用文件中
2、将#pragma comment(lib,“xxx.lib”)添加到调用文件中
3、加入函数的声明
extern “C” _declspec(dllimport) _stdcall int Plus(int x,int y);
导出则为dllexport,dll导出和导入的方式必须一致,即导出的时候使用了_stdcall,导入的时候也应该是__stdcall
这样的话如果需要修改函数,只需要在dll文件修改即可,程序不用编译
¶显示链接
1、定义函数指针
typedef int (__stdcall *lpPlus)(int,int);
2、声明函数指针变量
lpPlus myPlus
3、动态加载dll到内存中
HINSTANCE hModule=LoadLibrary(“DllDemo.dll”);
4、获取函数地址
myPlus=(lpPlus)GetProcAddress(hModule,“_Plus@8”)😭__stdcall为了区分会自动加符号),如果导入的时候没加stdcall就不需要加符号,即myPlus=(lpPlus)GetProcAddress(hModule,“Plus”);
5、调用函数
int a=myPlus(1,2);
¶特别说明
Handle是代表系统内核的对象,如文件句柄、线程句柄、进程句柄
HMODULE代表应用程序载入的模块-在内存中拉伸的起始位置
HINSTANCE在win32是和前一个一样的 win16遗留
HWND是窗口句柄
上面的都是无符号整数,四个字节
这样做是为了方便区分,操作系统给的
¶def文件导出
为了隐藏函数的名字
和前面的类似,先创建动态链接库,头文件只需要函数声明
创建def文件后,在def文件中写入
EXPORTS
(函数名) 编号
Plus @12——导出序号是12
在编号后面+NONAME 可以隐藏函数名
¶dll导出函数的方式
extern表示是个全局函数,可以供各个其他的函数调用
声明导出:_declspec(dllexport)
def文件导出
dll函数调用
隐式链接
包含头文件,载入lib库
显式链接
LoadLibary,GetProAddress
¶导出表
作用:记载我们写的dll或者exe导出的函数
¶导出表重要成员
1、指向导出表文件名的字符串-DWORD Name
2、导出函数的起始序号-DWORD Base
3、导出函数地址表RVA-DWORD AddressOfFunctions
4、函数名称地址表RVA-DWORD AddressOfNames
5、函数序号地址表RVA-DWORD AddressOfNameOrdinals
¶定位导出表
1、找出导出表RVA的偏移
首先我们要在数据目录的导出表信息的第一项,也就是导出表地址的RVA偏移是多少

可以看出c000h是RVA偏移,大小是164个字节
¶判断属于哪一个节
根据节区的VIrtualAddress判断

所以可以知道在.edata节
¶算出FOA位置
我们知道是在.rdata节的,可以算出FOA
FOA=RVA-节区的RVA(VirtualAddress)+节.PointerOfRawData
计算发现为8200h
¶通过FOA找到导出表位置
找到后根据前面的导出表大小可以知道导出表的范围
跳转过去即可

¶导出表的存储方式
一个导出表大小为0x28个字节,也就是两行半
分段讲解

前面十二个字节没用,就不讲了
¶Dword Name
绿框的4个字节存储的是dll名称的RVA,想查看的话,可以计算FOA,和前面一样的,得到8250地址存储的是我们的dll名称,以00结尾

¶Dword Base
导出函数的起始序号
DLL导出的函数如果给序号了,那么就从这个序号开始

¶Dword NumberOfFunctions-所有的导出函数的个数
前四个

¶DWORD NumberOfNames-以名字(有名字的)导出的函数的个数
可以将两个不同的名字指向相同的地址
有一些是无名函数不会在里面
后四个

下面就是子表了,三个子表都是RVA,要转为FOA

分别是函数地址表0x8228,函数名称表0x8238,函数序号表0x8248
先去找函数名称表,根据名称的下标再去序号表找对应,然后再去函数地址表找
¶函数地址表-AddressOfFunctions
函数地址表指向一个偏移,这个偏移存放了所有导出函数的地址,每个地址占四个字节,存放的是RVA地址

ImageBase+函数偏移就是函数在内存中的实际地址

可以看到这就是函数
还需要注意的就是,如果你按照序号导出1 3 4 5这4个函数,在导入表中我们的函数地址表中的地址会有5个,原因就是:中断的序号会给我们用0填充,2虽然没有,但是也会给我们导出.
¶函数名称表-AddressOfNames
函数名称表也是存储名称的RVA,四个字节存储一个,RVA的个数由以函数名称导出函数个数来决定(DWORD NumberOfNames)

转为FOA就是0x805e,0x8071,0x8082,0x8093

排序的时候是按照字母顺序排列的,而不是按照导出时函数的顺序进行排序的
例如:
EXPORT
SUB
ADD
MUL
导出三个函数,那么第一项就为 ADD,因为按照字母排序,A在前边,后面依次类推,所以我们上面看到的函数名称 ACquireSRW 这个函数名称,并不是第一个导出的函数.
¶函数序号表-AddressOfNumberOrdinals-存储的是RVA
给名称用的中转表

和函数名称表大小相同
¶按名称导出
得到函数名称后去AddressOfNames中的函数名称对比,得到索引后根据索引取出AddressOfNameOrdinals存储的值,以此为索引去函数地址表找到函数的地址
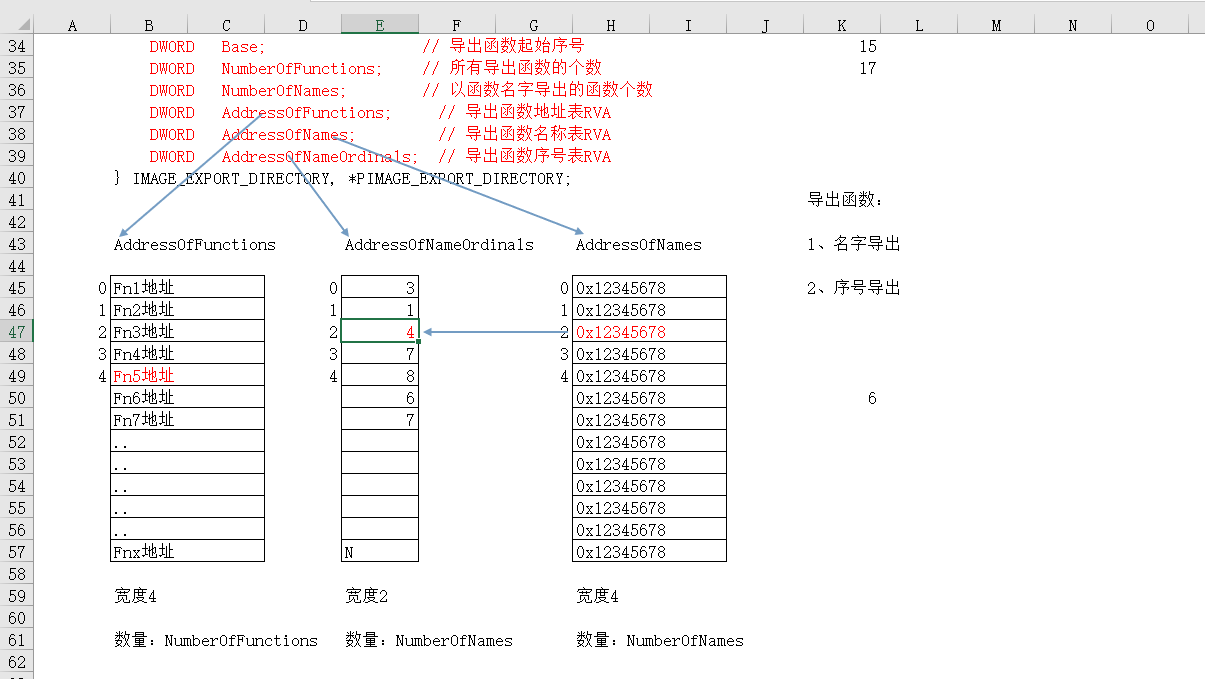
函数数量计算方式=最大序号-最小序号+1,(连续的算得准)不连续的话在函数地址表会留有多余的地址,但是多余的地址没有被使用
¶按序号导出
当使用序号导出的时候不需要使用序号表,直接将序号-Base作为索引去函数地址表找即可
¶导出的过程
系统和我们前面说的不一样
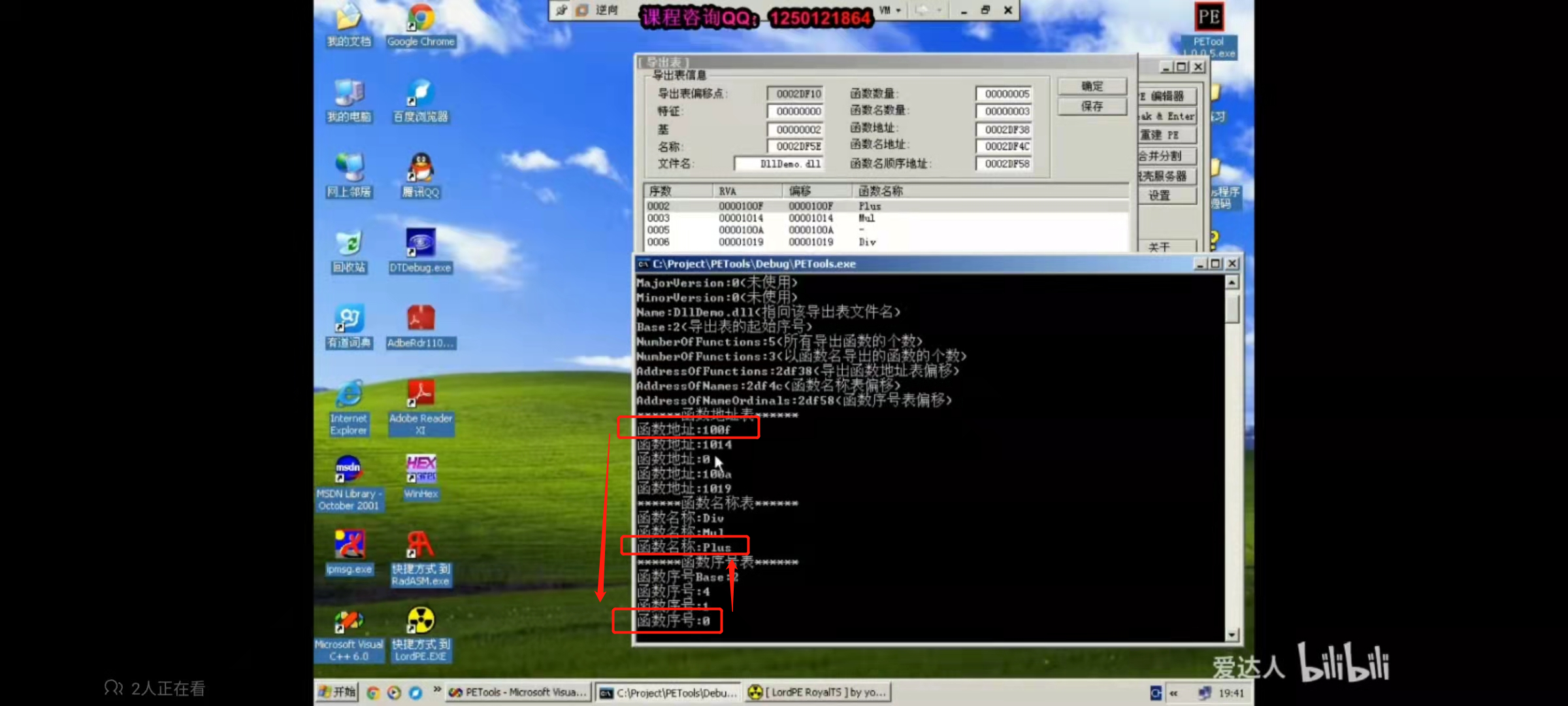
根据函数地址表找,如果索引在序号表中,说明是按名字导出的,再去名称表找对应,索引和序号表中的相同

这里的100a索引是3,在序号表中没有,所以不是按照序号导出的,序号可算,为索引+Base=005
¶重定位表-struct IMAGE_DATA_DIRECTORY BaseRelocationTable
¶程序的加载过程
系统加载的dll一般在高空间运行,一般是71**************
先像贴图一样把dll贴在内存中,最后指向exe文件的入口点,exe开始运行
我们自己写的dll的imageBase都是1000000,所以当多个dll同时使用,会存在地址已经被占用的问题,所以dl只能往后放,但是:
编译器生成的地址=ImageBase+RVA,这个地址在程序编译完成后,已经写入文件了。但是如果当程序加载时没有按照原来的ImageBase载入,但是此时程序还是会按照前面生成的地址进行使用
所以一般exe不存在重定位表,而dll一般都有,用于记录需要修改的地方
¶重定位表解析
重定位表是分块,根据RVA计算得到FOA,跳转过去发现有几个重定位表

这两个数据分别存储RVA和大小

下面的数据中,每两个字节代表这一段有多少个数据需要修复,一般是绝对地址需要修改

只需要基础地址加上小表的值就可以定位到需要修改的地方,而不用四个字节来存储地址,节省了空间,而这个基础地址就是前面记录的RVA
而基础地址可以不同,所以才需要分块操作
可以发现每一块的间隔是1000h,也就是内存对齐的大小
一个页是1000h,所以只需要1000个十六进制的地址就可以记录完一页的每个位置,对应十进制的4096个
2^12=4096,所以只需要十二个二进制位就可以表示完所有可能,两个字节有十六位,所以最后找地址的时候,只用取低十二位,高四位有别的用处-如果高四位的值是3就说明这个地方需要修改
¶判断块数
下一块的开始地址都可以通过RVA+SizeOfBlock来得到
直到遇到全为零的块
计算需要修改的数据个数:(SizeOfBlock-8)/2,因为前面两个数据是8个字节,剩下的两个字节为1组
¶移动导出表-重定位表
表的数据也在节区中,加密代码时,表的信息也会被加密,这样程序无法初始化,所以要先增节,再移动表,学会移动各种表是对程序加密和破解的基础
¶移动导出表
比较繁琐,因为要移动多张表
¶在DLL文件中新增节
先计算大小
并且返回新增节的FOA,因为后面的数据还要从新增节的开头开始
¶复制数据
需要复制的数据类型和长度
¶复制AddressOfFunctions
长度:4×NumberOfFunctions
¶复制AddressOfNameOrdinals
长度:2×NumberOfNames
¶复制AddressOfNames
长度:4×NumberOfNames
¶复制所有函数名
长度不确定,复制时直接修复AddressOfName(因为名字的地址也改变了),每复制完一个名字,都需要计算下一个复制的地方
¶复制导出表的整体结构
¶修复地址
AddressOfName
目录项指向新的导出表的位置
函数地址表、序号表、名称表都需要修复
¶将目录项中的RVA修正
指向我们新的导出表的位置
¶移动重定位表
直接复制过去,修改RVA即可
加载程序:(当前面已经有DLL被加载)
1、将新的DLL复制到新的位置
2、修复重定位表,修改每一个重定位表的偏移
¶导入表
作用:从其他第三方程序导入API,以供本程序调用
在exe运行的时候加载器会遍历导入表,将导入表中所有dll加载到进程中,被加载的DLL的DLLMain就会被调用
通过导入表可以知道程序使用了哪些函数
导入表,是为了提供的要导入的dll的函数的地址,只不过由于dll地址不固定,所以每次都会重新修正
¶导入表解析
¶重要字段
1 | DWORD OriginalFirstThunk; |
指向导入名称表(INT)的RVA
1 | DWORD FirstThunk; |
指向导入地址表(IAT)的RVA
1 | DWORD Name; |
指向导入映像文件的名字

计算后跳转过去,注意要算的是FOA,但是这里RVA和FOA一样

其中IAT与INT都指向 IMAGE_THUNK_DATA32(虽然二者的地址不同)
INT-以全0结尾
 函数名数组(对应IMAGE_THUNK_DATA32结构体数组,每一个结构体就是一个联合体-4字节)
函数名数组(对应IMAGE_THUNK_DATA32结构体数组,每一个结构体就是一个联合体-4字节)
1 | typedef struct _IMAGE_THUNK_DATA32{ |
¶导入表结构
在可选PE头最后的十六个数组的导入表结构,这里存放的是RVA

跳转过去发现存储的是struct IMAGE_IMPORT_DESCRIPTOR ImportDescriptor[0],这里存放的是真正的导入表结构
有多少个DLL,对应的结构体数组就有几个
关键的数据有下面三个,也要注意这里的TimeDateStamp-时间戳

¶INT表
ULONG OriginalFirstThunk-RVA,存放的是IMAGE_THUNK_DATA这个结构体数组,四字节数,以0结尾
跳转过去

但是之前学导出表有了解到,导出函数可以以名字导出,亦可以序号导出。所以为了方便区分,就将这INT表的每个值做了细微调整。
如果这个4字节数的最高位(二进制)为1,那么抹去这个最高位之后,所表示的数就是要导入的函数的序号;如果最高位是0,那这个数就也是一个RVA,指向IMAGE_IMPORT_BY_NAME结构体(包含真正的导入函数的名字字符串,以0结尾)。INT表以4字节0结尾。
根据INT存储的RVA进行跳转
¶struct _IMAGE_IMPORT_BY_NAME
1、WORD Hint,可能为0,编译器决定,如果不为0,则是函数在导出表中的索引
2、BYTE Name[1],函数名称,以0结尾
¶NAME
DLL的名字,以0结尾

¶ULONG FirstThunk
根据RVA跳转,发现存储的值和INT的一样,这个存储的是IAT,当文件加载后,会发现IAT会改变
¶IAT表-导入地址表
记录程序正在使用哪些库中的哪些函数
分为两个过程,在文件中存储的是存放函数的地址,在内存中存放函数
在文件运行前类似于call [地址]
在文件运行时类似于call [上面地址存放的值,也就是函数]
¶IAT表存在的原因
一般程序在调用自身函数的时候,自身函数地址RVA是固定的;但是当程序在调用dll里的函数的时候,由于dll的地址会发生重定位,导致dll里的函数地址每次都会发生变化。
为了准确调用dll函数的地址,构造了IAT表来存储程序运行时,即DLL文件重定位之后的dll函数的位置。

¶导入表加载过程
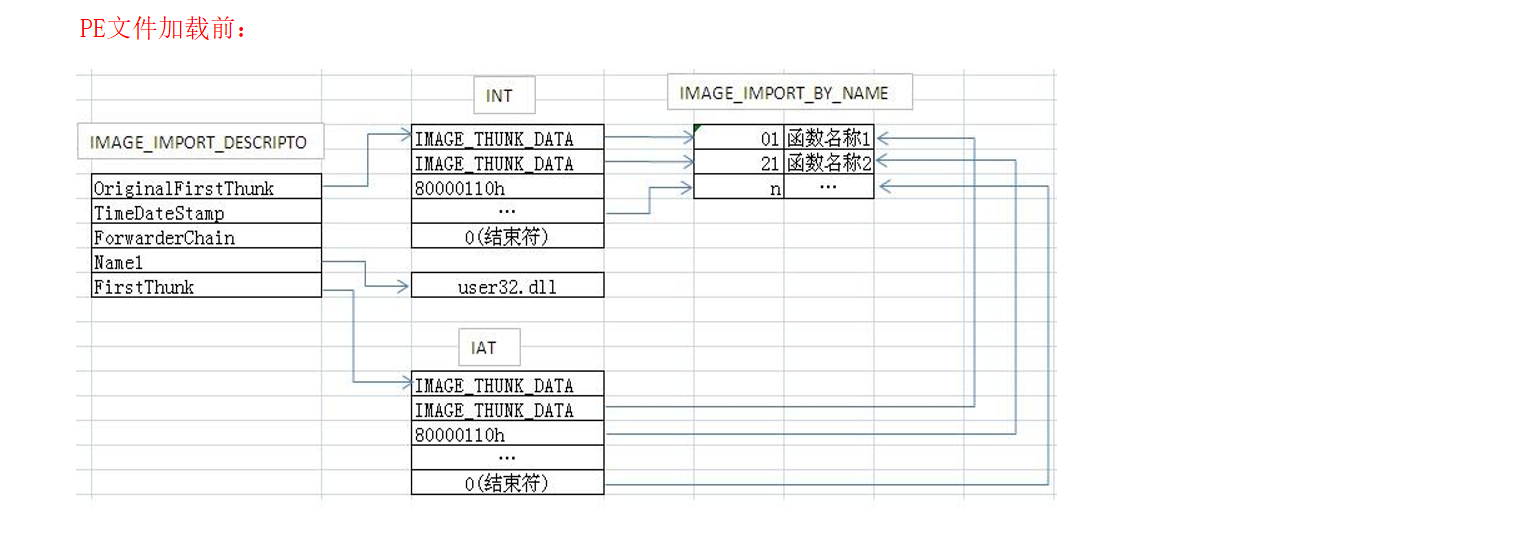
加载过程
先找DLL,再确定使用的函数
¶寻找DLL
先根据导入表的NAME找到DLL名称和DLL的INT和IAT表,开始的时候INT和IAT数据相同,但是存储位置不同,INT和IAT表都指向IMAGE_THUNK_DATA
¶查INT表
因为导出的时候可以按序号导出也可以按函数名称导出,所以为了区分,image_thunk_data最高位为1时,表示其存储的是序号,而剩下的31位表示序号,否则image_thunk_data存储的是IMAGE_BY_NAME的RVA
因为GetProc可以通过序号找到函数地址,也可以使用名称找到,所以通过这种方式找到函数的地址,然后填充至IAT中
¶修改IAT
使用GETProAddr(module)
将前面查找到的函数地址填充进IAT表中
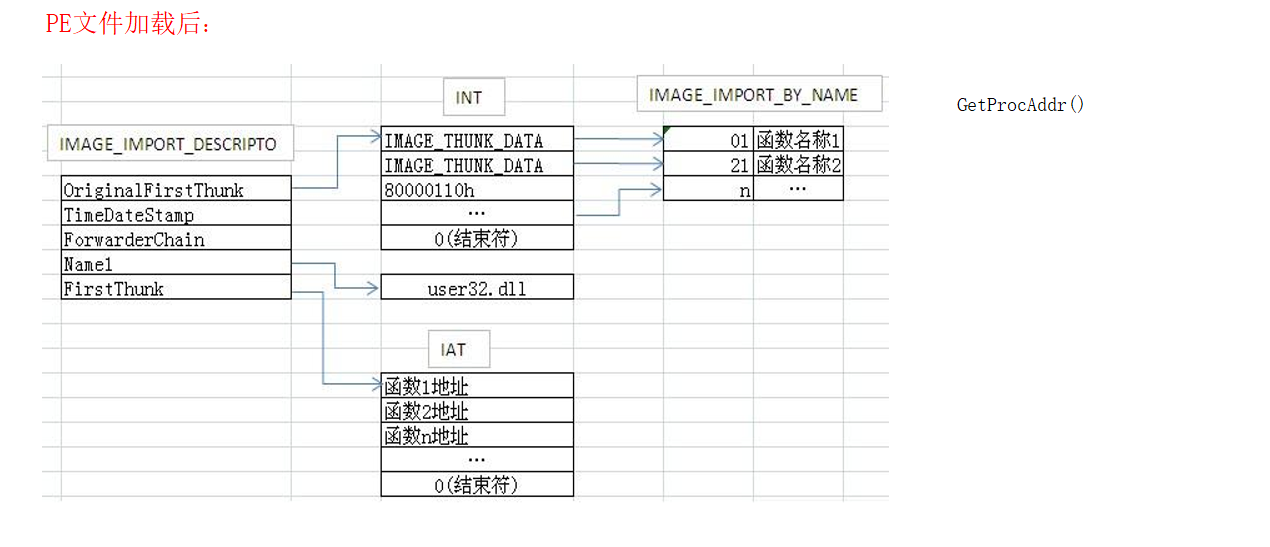
可以看到IAT表变成了函数的地址
IAT表会存储dll的函数的地址,方便调用该函数时,直接取IAT表这个地址内的值,作为函数地址,去CALL。
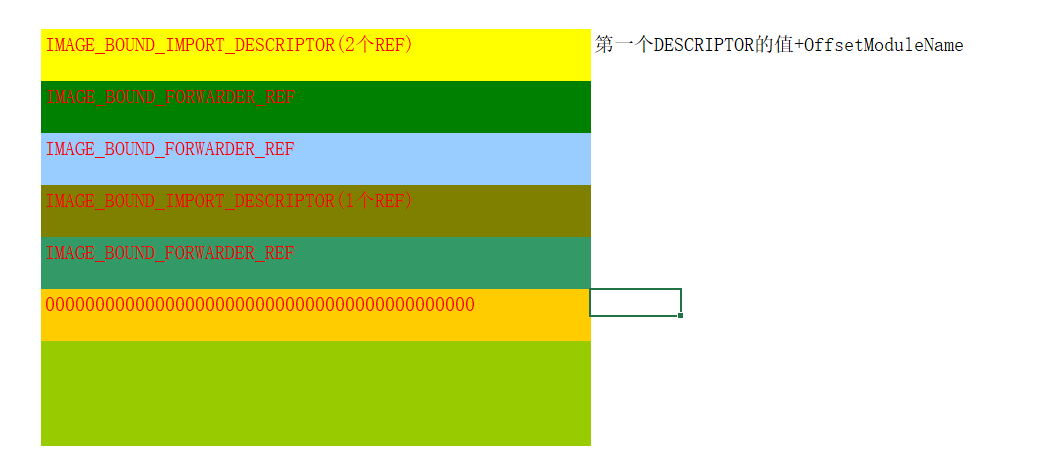
¶绑定导入表- struct _IMAGE_BOUND_IMPORT_DESCRIPTOR
可选NT头里的结构

¶作用
有些windows程序,如notepad,为了提高加载速度,会直接把DLL中的函数地址写入到IAT表,省去了加载时的计算。
¶可能存在的问题
第一,当DLL没有占住ImageBase时,IAT中的地址就是错的;第二,当链接的DLL被修改了,那IAT里写的地址也是错的。遇到这两种情形之一,加载时就必须修复IAT了。
对于第二种情形,DLL是否被修改,是根据比较DLL的时间戳和绑定导入表中的记录的DLL时间戳来判断的,如果不一致,说明DLL被修改了。
加载程序时,操作系统根据导入表中的时间戳来判断程序是否使用了绑定导入。当时间戳为0,表示不使用绑定导入表;当时间戳为0xFFFFFFFF,说明该程序使用绑定导入。
¶绑定导入表结构
1 | typedef struct _IMAGE_BOUND_IMPORT_DESCRIPTOR { |
TimeDateStamp 是时间戳,用于和DLL中的时间戳比较,判断DLL是否已经发生变化;
OffsetModuleName 是当前模块名距离第一个 _IMAGE_BOUND_IMPORT_DESCRIPTOR 的偏移。
NumberOfModuleForwarderRefs 是该模块依赖的模块数量;
¶依赖模块结构
1 | typedef struct _IMAGE_BOUND_FORWARDER_REF { |
除了第三个属性保留,其他与 _IMAGE_BOUND_IMPORT_DESCRIPTOR 相同。